TL;DR: We introduce Scaffold-GS, which uses anchor points to distribute local 3D Gaussians, and predicts their attributes on-the-fly based on viewing direction and distance within the view frustum.
Our method converges faster, uses fewer primitives, and achieves better visual quality.

Our method performs superior on scenes with challenging observing views. e.g. transparency, specularity, reflection, texture-less regions and fine-scale details.
Method Overview
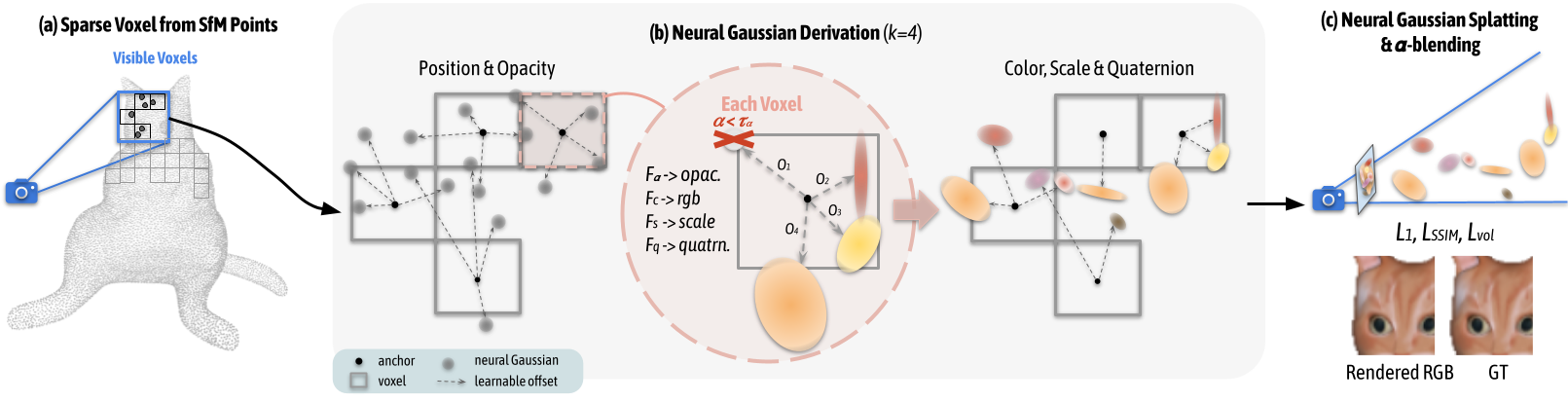
Framework. (a) We start by forming a sparse voxel grid from SfM-derived points. An anchor associated with a learnable scale is placed at the center of each voxel, roughly sculpturing the scene occupancy. (b) Within a view frustum, k neural Gaussians are spawned from each visible anchor with offsets. Their attributes, i.e. opacity, color, scale and quaternion are then decoded from the anchor feature, relative camera-anchor viewing direction and distance using MLPs. (c) Note that to alleviate redundancy and improve efficiency, only non-trivial neural Gussians are rasterized. The rendered image is supervised via reconstruction, structural similarity, and a volume regularization.

Anchor refinement. We propose an error-based anchor growing policy to reliably grow new anchors where neural Gaussians find significant. We quantize neural Gaussians into multi-resolution voxels and add new anchors to voxels with gradients larger than level-wise thresholds. Our strategy effectively improves scene coverage without using excessive points.
